CI/CD 파이프라인은 코드 변경이 발생했을 때 빌드, 테스트, 배포를 자동으로 실행하는 워크플로우입니다. 수동 배포의 실수와 지연을 줄이고, 코드 품질을 일관되게 유지하는 것이 핵심 목적입니다.
핵심 요약
- CI(Continuous Integration)는 코드 변경을 자주 통합하고, 빌드와 테스트를 자동 실행하는 프로세스입니다.
- CD는 Continuous Delivery(수동 승인 후 배포)와 Continuous Deployment(자동 배포)로 구분됩니다.
- 파이프라인의 기본 단계는 Source → Build → Test → Deploy이며, 조직에 따라 보안 스캔, 승인 게이트 등이 추가됩니다.
- 도구 선택보다 "어떤 단계에서 무엇을 검증할 것인가"를 먼저 설계하는 것이 중요합니다.
- 파이프라인 실패 시 빠른 피드백과 롤백 전략이 운영 안정성을 결정합니다.
1. 왜 CI/CD가 필요한가
백엔드 개발자 4명이 하나의 서비스를 개발하고 있다고 가정합니다.
금요일 오후, 각자 작업한 코드를 main 브랜치에 합치고 수동으로 서버에 배포합니다. 이때 발생하는 문제들:
- A의 코드와 B의 코드가 충돌합니다. 금요일 저녁에 충돌을 해결하느라 야근합니다.
- 수동 배포 중 설정 파일 하나를 빠뜨려서 프로덕션에서 500 에러가 발생합니다.
- "내 로컬에서는 됐는데"라는 말이 반복됩니다. 빌드 환경이 개발자마다 다르기 때문입니다.
- 문제가 생겨도 "언제 어떤 커밋이 문제인지" 추적하기 어렵습니다.
CI/CD는 이 문제들을 구조적으로 해결합니다.
| 문제 | CI/CD가 해결하는 방식 |
|---|---|
| 코드 충돌 누적 | 매 커밋마다 통합 → 충돌을 조기에 발견 |
| 수동 배포 실수 | 배포 과정을 코드로 정의 → 매번 동일하게 실행 |
| 환경 차이 | 빌드/테스트를 동일한 컨테이너에서 실행 |
| 문제 추적 어려움 | 커밋 단위로 빌드/테스트 결과가 기록됨 |
| 배포 지연 | 자동화로 배포 주기를 단축 (주 1회 → 일 수회) |
2. CI와 CD의 정의
CI — Continuous Integration
코드 변경을 공유 브랜치에 자주 통합하고, 통합할 때마다 자동으로 빌드와 테스트를 실행하는 프로세스입니다.
핵심은 "자주, 작게, 빨리"입니다. 일주일치 코드를 한 번에 합치는 것이 아니라, 하루에도 여러 번 작은 단위로 통합합니다. 통합할 때마다 자동 테스트가 돌아가므로 문제를 빠르게 발견할 수 있습니다.
CI가 보장하는 것: - 코드가 빌드됩니다 (컴파일 에러 없음) - 기존 기능이 깨지지 않았습니다 (테스트 통과) - 코드 품질 기준을 충족합니다 (린트, 정적 분석)
CD — Continuous Delivery vs Continuous Deployment
CD는 두 가지 의미로 사용됩니다. 조직의 위험 허용도에 따라 선택이 달라집니다.
| 구분 | Continuous Delivery | Continuous Deployment |
|---|---|---|
| 정의 | 배포 가능한 상태를 항상 유지 | 테스트 통과 시 자동으로 프로덕션 배포 |
| 프로덕션 배포 | 수동 승인 후 실행 | 자동 실행 |
| 적합 환경 | 규제 산업, 대규모 서비스 | 빠른 반복이 필요한 서비스 |
| 위험도 | 낮음 (사람이 최종 판단) | 높음 (테스트 품질에 의존) |
실무에서는 Continuous Delivery를 기본으로 채택하고, 테스트 커버리지와 모니터링이 충분히 성숙한 후에 Continuous Deployment로 전환하는 경우가 많습니다.
"우리 팀은 CD를 하고 있다"고 할 때, Delivery인지 Deployment인지 명확히 구분해야 합니다. 면접에서도 자주 물어보는 포인트입니다. 핵심 차이는 "프로덕션 배포에 사람의 승인이 필요한가"입니다.
3. 파이프라인 기본 구조

CI/CD 파이프라인은 일반적으로 다음 단계로 구성됩니다.
Stage 1: Source (소스 코드 변경 감지)
파이프라인의 트리거입니다. 코드가 변경되면 파이프라인이 시작됩니다.
- 트리거 조건: push, pull request, tag 생성, 스케줄(cron)
- 소스 저장소: GitHub, GitLab, Bitbucket, AWS CodeCommit
설계 관점에서 중요한 결정: "어떤 브랜치의 어떤 이벤트에서 파이프라인을 실행할 것인가?"
# GitHub Actions 예시: main 브랜치 push와 PR에서만 실행
on:
push:
branches: [main]
pull_request:
branches: [main]
모든 브랜치에서 전체 파이프라인을 실행하면 비용과 시간이 낭비됩니다. 일반적으로 feature 브랜치에서는 빌드+테스트만, main 브랜치에서는 전체 파이프라인을 실행합니다.
Stage 2: Build (빌드)
소스 코드를 실행 가능한 형태로 변환합니다.
- 컴파일 언어: Java → JAR/WAR, Go → 바이너리, TypeScript → JavaScript
- 컨테이너 환경: Docker 이미지 빌드 → 레지스트리에 Push
- 프론트엔드: npm build → 정적 파일 생성
# Docker 이미지 빌드 예시
- name: Build Docker Image
run: |
docker build -t my-app:${{ github.sha }} .
docker push registry.example.com/my-app:${{ github.sha }}
빌드 단계에서의 설계 포인트:
| 고려사항 | 설명 |
|---|---|
| 재현 가능성 | 같은 커밋에서 항상 같은 결과물이 나와야 함 |
| 캐싱 | 의존성 다운로드를 캐싱해서 빌드 시간 단축 |
| 이미지 태깅 | commit SHA를 태그로 사용하면 추적이 쉬움 |
| 멀티 스테이지 빌드 | 빌드 도구는 최종 이미지에 포함하지 않음 (이미지 크기 감소) |
Stage 3: Test (테스트)
빌드된 결과물이 기대대로 동작하는지 검증합니다. 테스트는 속도와 범위에 따라 계층적으로 구성합니다.
| 테스트 유형 | 실행 시간 | 검증 범위 | 파이프라인 위치 |
|---|---|---|---|
| Unit Test | 초 단위 | 함수/클래스 단위 | 모든 커밋 |
| Integration Test | 분 단위 | 모듈 간 연동 | PR merge 시 |
| E2E Test | 분~십분 | 전체 사용자 시나리오 | 배포 전 |
| Performance Test | 십분 이상 | 부하 처리 능력 | 릴리스 전 |
# 테스트 단계 예시
- name: Unit Tests
run: npm test -- --coverage
- name: Integration Tests
run: npm run test:integration
services:
postgres:
image: postgres:15
env:
POSTGRES_PASSWORD: test
설계 관점에서의 trade-off: 테스트를 많이 넣을수록 안전하지만 파이프라인이 느려집니다. 일반적으로 "빠른 테스트를 먼저, 느린 테스트를 나중에" 배치하고, 빠른 테스트가 실패하면 느린 테스트는 실행하지 않는 전략을 사용합니다.
Stage 4: Deploy (배포)
테스트를 통과한 결과물을 실제 환경에 배포합니다.
배포 환경은 일반적으로 다단계로 구성합니다:
Staging → (승인) → Production
또는 더 세분화하면:
Dev → QA → Staging → (승인) → Production
왜 다단계인가? 프로덕션에서 문제가 발생하면 사용자에게 직접 영향을 줍니다. Staging에서 먼저 검증하면 프로덕션 장애를 줄일 수 있습니다. 다만 환경이 많을수록 유지 비용이 증가하므로, 팀 규모와 서비스 중요도에 따라 결정합니다.
# 배포 단계 예시 (GitHub Actions)
deploy-staging:
needs: [test]
runs-on: ubuntu-latest
environment: staging
steps:
- name: Deploy to Staging
run: kubectl apply -f k8s/staging/
deploy-production:
needs: [deploy-staging]
runs-on: ubuntu-latest
environment:
name: production
url: https://my-app.example.com
steps:
- name: Deploy to Production
run: kubectl apply -f k8s/production/
GitHub Actions의
environment 설정을 사용하면 특정 환경에 대해 수동 승인(Required Reviewers)을 설정할 수 있습니다. Continuous Delivery 패턴을 구현하는 가장 간단한 방법입니다.4. 동작 원리: 전체 흐름
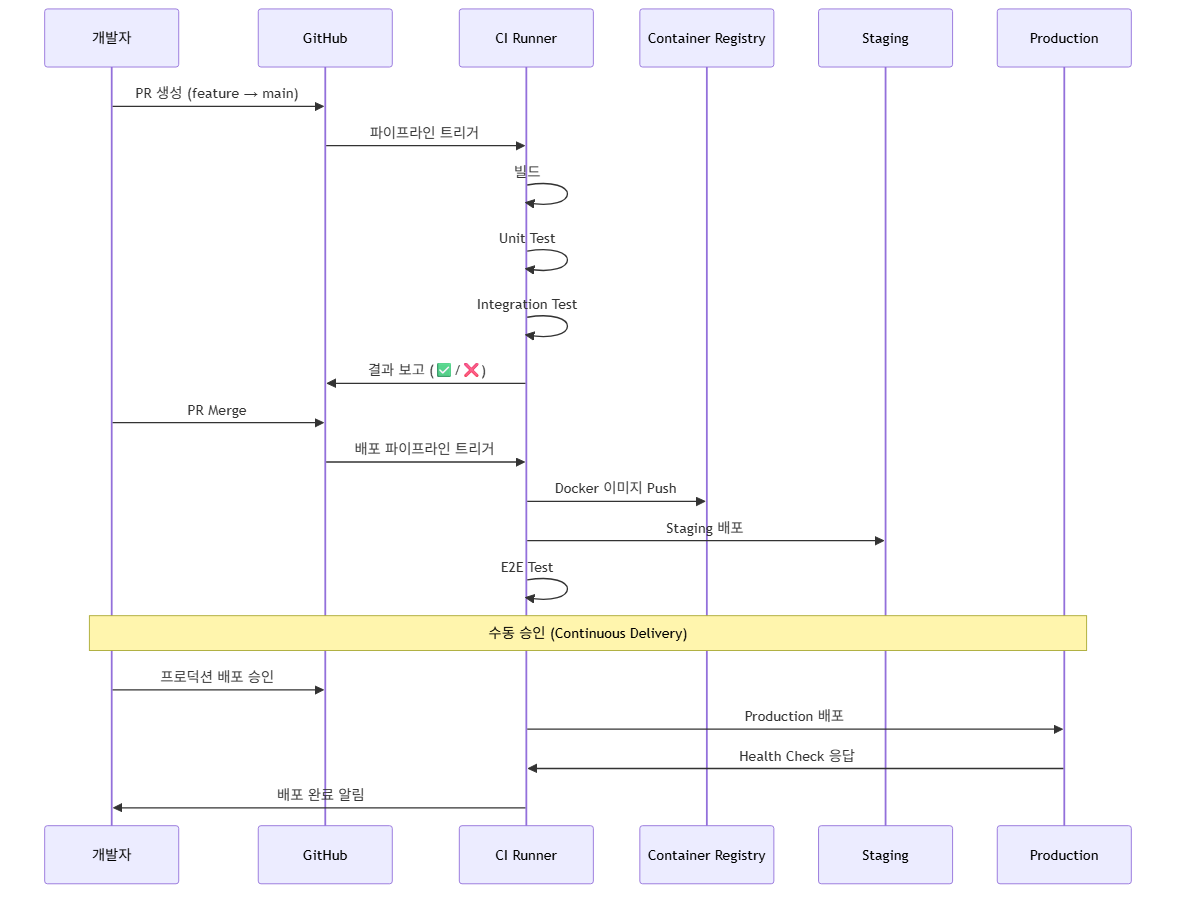
실무 시나리오로 전체 흐름을 설명합니다.
시나리오: 로그인 API 버그 수정 배포
- 개발자가 버그를 수정하고 feature 브랜치에서 PR을 생성합니다.
- CI 시작: PR 생성 이벤트가 파이프라인을 트리거합니다.
- Build: Docker 이미지를 빌드합니다.
- Test: Unit Test → Integration Test 순서로 실행합니다.
- PR 상태 업데이트: 테스트 결과가 PR에 표시됩니다 (✅ 또는 ❌).
- 코드 리뷰: 팀원이 코드를 리뷰하고 승인합니다.
- Merge: main 브랜치에 병합됩니다.
- CD 시작: main 브랜치 push 이벤트가 배포 파이프라인을 트리거합니다.
- Staging 배포: Staging 환경에 자동 배포됩니다.
- Staging 검증: 자동 E2E 테스트 또는 수동 QA를 진행합니다.
- 승인: 팀 리드가 프로덕션 배포를 승인합니다.
- Production 배포: 프로덕션에 배포됩니다.
- 모니터링: 배포 후 에러율, 응답 시간을 모니터링합니다.
이 흐름에서 핵심 원칙은 "빠른 피드백"입니다. 개발자가 PR을 올린 후 10분 안에 빌드/테스트 결과를 받을 수 있어야 합니다. 30분 이상 걸리면 개발자가 다른 작업으로 컨텍스트를 전환하고, 피드백을 무시하게 됩니다.
5. 실무 사용 사례
사례 1: 스타트업 — GitHub Actions 기반 단순 파이프라인
5명 규모의 백엔드 팀에서 Node.js API 서버를 운영합니다. 인프라는 AWS ECS를 사용합니다.
요구사항: - 빠른 배포 주기 (하루 2~3회) - 인프라 운영 부담 최소화 - 비용 효율적
파이프라인 설계:
name: CI/CD Pipeline
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install Dependencies
run: npm ci
- name: Lint
run: npm run lint
- name: Unit Test
run: npm test -- --coverage
- name: Build Docker Image
run: docker build -t my-app:${{ github.sha }} .
deploy:
needs: [ci]
if: github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
environment: production
steps:
- name: Deploy to ECS
run: |
aws ecs update-service \
--cluster my-cluster \
--service my-service \
--force-new-deployment
왜 이렇게 설계했는가:
- GitHub Actions를 선택한 이유: 별도 CI 서버 운영 불필요, GitHub과 통합이 자연스러움, 소규모 팀에서 무료 티어로 충분
- Staging 환경을 생략한 이유: 5명 팀에서 별도 환경 유지 비용이 크고, 테스트 커버리지로 대체 가능하다고 판단
environment: production으로 수동 승인을 넣은 이유: 완전 자동 배포는 테스트 커버리지가 90% 이상일 때 검토
trade-off: - Staging이 없으므로 프로덕션에서 환경 차이로 인한 문제가 발생할 수 있음 - 이를 보완하기 위해 Feature Flag를 사용해 새 기능을 점진적으로 활성화
사례 2: 중규모 팀 — 멀티 환경 + 보안 스캔 포함
20명 규모의 팀에서 마이크로서비스 3개를 운영합니다. 금융 관련 서비스라 보안 요구사항이 있습니다.
추가 요구사항: - 보안 취약점 스캔 필수 - 프로덕션 배포 전 QA 팀 검증 - 감사 로그 (누가 언제 배포했는지)
파이프라인 구조:
Source → Build → Unit Test → SAST → Container Scan
→ Deploy Staging → Integration Test → QA 승인
→ Deploy Production → Smoke Test → 모니터링
이 구조에서 추가된 단계:
| 단계 | 도구 예시 | 목적 |
|---|---|---|
| SAST | SonarQube, Semgrep | 코드 내 보안 취약점 탐지 |
| Container Scan | Trivy, Snyk | Docker 이미지 내 CVE 탐지 |
| QA 승인 | GitHub Environment Protection | 사람이 최종 판단 |
| Smoke Test | 배포 후 핵심 API 호출 | 배포 직후 정상 동작 확인 |
왜 SAST를 테스트 후에 배치하는가?
SAST는 실행 시간이 수 분 걸릴 수 있습니다. Unit Test가 실패하면 코드 자체에 문제가 있으므로 보안 스캔까지 갈 필요가 없습니다. "빠른 실패 우선" 원칙에 따라 빠른 검증을 앞에 배치합니다.
6. 주요 CI/CD 도구 비교
| 도구 | 유형 | 장점 | 단점 | 적합 환경 |
|---|---|---|---|---|
| GitHub Actions | SaaS | GitHub 통합, 마켓플레이스, 무료 티어 | GitHub 종속, 복잡한 워크플로우 한계 | GitHub 사용 팀 |
| GitLab CI | SaaS/Self-hosted | GitLab 통합, 자체 Runner 가능 | GitLab 종속 | GitLab 사용 팀 |
| Jenkins | Self-hosted | 높은 유연성, 플러그인 생태계 | 운영 부담, 설정 복잡 | 대규모 조직, 레거시 |
| AWS CodePipeline | SaaS | AWS 서비스 통합 | AWS 종속, 유연성 낮음 | AWS 올인 환경 |
| CircleCI | SaaS | 빠른 실행, Docker 지원 | 비용 증가 가능 | 빠른 빌드가 중요한 팀 |
| Argo CD | Self-hosted | GitOps 네이티브, K8s 특화 | CD만 담당 (CI 별도 필요) | Kubernetes 환경 |
도구 선택 기준:
- 소스 저장소와의 통합: GitHub을 쓰면 GitHub Actions, GitLab을 쓰면 GitLab CI가 자연스럽습니다.
- 운영 부담: SaaS는 관리가 편하지만 커스터마이징에 한계가 있습니다. Self-hosted는 유연하지만 직접 운영해야 합니다.
- 비용: 오픈소스 프로젝트는 대부분 무료 티어로 충분합니다. 상용 프로젝트는 빌드 시간에 따라 비용이 증가합니다.
- 보안 요구사항: 코드가 외부로 나가면 안 되는 환경에서는 Self-hosted Runner나 Jenkins를 검토합니다.
도구를 먼저 선택하고 파이프라인을 설계하는 것은 순서가 반대입니다. "어떤 단계가 필요한가 → 각 단계에서 무엇을 검증할 것인가 → 이를 지원하는 도구는 무엇인가" 순서로 접근하는 것이 좋습니다.
7. 보안 고려사항
CI/CD 파이프라인은 코드 저장소, 클라우드 인프라, 프로덕션 환경에 모두 접근할 수 있는 강력한 권한을 가집니다. 파이프라인이 침해되면 공급망 공격(Supply Chain Attack)으로 이어질 수 있습니다.
Secret 관리
파이프라인에서 사용하는 인증 정보(API 키, 클라우드 자격 증명 등)는 코드에 하드코딩하면 안 됩니다.
| 방법 | 설명 | 적합 환경 |
|---|---|---|
| GitHub Secrets | 저장소/조직 레벨 암호화 저장 | GitHub Actions |
| AWS Secrets Manager | 중앙 집중 Secret 관리 | AWS 환경 |
| HashiCorp Vault | 멀티 클라우드 Secret 관리 | 대규모/멀티 클라우드 |
| OIDC Federation | 장기 자격 증명 없이 임시 토큰 발급 | 클라우드 환경 권장 |
# OIDC를 사용한 AWS 인증 (장기 키 불필요)
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: arn:aws:iam::123456789012:role/github-actions-role
aws-region: ap-northeast-2
파이프라인 보안 체크리스트
- Secret을 환경 변수로 주입하고, 로그에 출력되지 않도록 마스킹 설정
- 서드파티 Action/Plugin은 버전을 고정 (SHA 기반 pinning 권장)
- 프로덕션 배포 권한은 최소 인원에게만 부여
- 파이프라인 설정 파일(.github/workflows/) 변경에 대한 코드 리뷰 필수
- Self-hosted Runner 사용 시 네트워크 격리 및 정기 패치
# Action 버전 고정 예시 (태그 대신 SHA 사용)
- uses: actions/checkout@b4ffde65f46336ab88eb53be808477a3936bae11 # v4.1.1
왜 SHA로 고정하는가? 태그는 변경될 수 있습니다. 악의적인 공격자가 인기 있는 Action의 태그를 덮어쓰면, 해당 Action을 사용하는 모든 파이프라인에 악성 코드가 주입될 수 있습니다. SHA는 변경 불가능하므로 이 위험을 차단합니다.
8. 비용/운영 고려사항
CI/CD 파이프라인의 실행 비용은 빌드 시간과 실행 빈도에 비례합니다. 최적화 없이 운영하면 월 수백 달러의 비용이 발생할 수 있습니다.
비용 구조
| 항목 | GitHub Actions 기준 | 비고 |
|---|---|---|
| 무료 티어 | Public 저장소 무제한, Private은 플랜별 상이 (Free: 2,000분/월, Pro: 3,000분/월) | 팀 규모에 따라 부족할 수 있음 |
| 추가 비용 | Linux 2-core $0.006/분, macOS 3-core $0.062/분 | macOS 빌드는 약 10배 비쌈 |
| Self-hosted Runner | 무료 (인프라 비용만) | 운영 부담 증가 |
| 스토리지 | Artifact 저장 용량에 따라 (Free: 500MB) | 오래된 Artifact 정리 필요 |
비용 최적화 전략
| 전략 | 효과 | 구현 난이도 |
|---|---|---|
| 의존성 캐싱 | 빌드 시간 30~50% 단축 | 낮음 |
| 병렬 실행 | 전체 파이프라인 시간 단축 | 중간 |
| 조건부 실행 | 변경된 파일에 따라 필요한 단계만 실행 | 중간 |
| Self-hosted Runner | 분당 비용 제거 | 높음 (운영 부담) |
| Docker 레이어 캐싱 | 이미지 빌드 시간 단축 | 낮음 |
# 의존성 캐싱 예시
- name: Cache node_modules
uses: actions/cache@v4
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-node-
운영 관점
파이프라인 실행 시간 목표:
| 단계 | 목표 시간 | 초과 시 검토 사항 |
|---|---|---|
| CI 전체 (빌드+테스트) | 10분 이내 | 테스트 병렬화, 캐싱 |
| 배포 (Staging) | 5분 이내 | 이미지 크기, 배포 전략 |
| 배포 (Production) | 5분 이내 | Rolling Update 설정 |
| 전체 파이프라인 | 20분 이내 | 단계 분리, 병렬화 |
CI가 10분을 넘으면 개발자가 피드백을 기다리지 않고 다음 작업으로 넘어갑니다. 이 경우 CI의 핵심 가치인 "빠른 피드백"이 사라집니다.
모니터링 지표:
- 파이프라인 성공률: 80% 미만이면 flaky test 정리 필요
- 평균 실행 시간: 추세가 증가하면 최적화 필요
- 배포 빈도: 주 1회 미만이면 파이프라인이 제 역할을 못하고 있을 수 있음
- 장애 복구 시간(MTTR): 롤백까지 걸리는 시간
9. 자주 하는 실수
1. 테스트 없이 CD만 구축
"배포 자동화"에만 집중하고 테스트를 생략하는 경우입니다. 빌드만 성공하면 바로 배포되므로, 런타임 에러가 프로덕션에 그대로 나갑니다. CI 없는 CD는 "실수를 더 빠르게 배포하는 시스템"이 됩니다.
2. 모든 것을 하나의 파이프라인에 넣기
빌드, 테스트, 보안 스캔, 배포, 알림을 하나의 워크플로우 파일에 넣으면 500줄이 넘어갑니다. 유지보수가 어렵고, 한 단계의 변경이 전체에 영향을 줍니다. 단계별로 워크플로우를 분리하고 workflow_call이나 needs로 연결하는 것이 좋습니다.
3. Secret을 코드에 하드코딩
"테스트용이니까 괜찮겠지"라고 생각하고 .env 파일이나 코드에 API 키를 넣는 경우입니다. Git 히스토리에 남으면 삭제해도 복구할 수 있습니다. 처음부터 Secret Manager를 사용하는 습관이 필요합니다.
4. 롤백 전략 없이 배포
배포는 자동화했지만 "문제가 생기면 어떻게 되돌리는가"를 정의하지 않은 경우입니다. 롤백 방법을 미리 정의하고 테스트해야 합니다. 이전 버전의 Docker 이미지를 다시 배포하는 것이 가장 단순한 롤백 전략입니다.
5. Flaky Test를 방치
간헐적으로 실패하는 테스트를 무시하면, 팀원들이 CI 실패를 "또 그거겠지"라고 넘기게 됩니다. 결국 실제 버그도 놓치게 됩니다. Flaky Test는 발견 즉시 수정하거나 격리해야 합니다.
6. 환경별 설정을 분리하지 않음
Staging과 Production이 같은 데이터베이스를 바라보거나, 같은 API 키를 사용하는 경우입니다. Staging에서 테스트 데이터를 넣다가 프로덕션 데이터를 오염시킬 수 있습니다. 환경별 설정은 환경 변수나 설정 파일로 완전히 분리해야 합니다.
10. 배포 전략 개요
파이프라인의 Deploy 단계에서 "어떻게 배포할 것인가"도 중요한 설계 결정입니다.
| 전략 | 설명 | 장점 | 단점 |
|---|---|---|---|
| Rolling Update | 인스턴스를 순차적으로 교체 | 추가 인프라 불필요 | 롤백 시간이 김 |
| Blue-Green | 새 환경을 준비하고 트래픽 전환 | 즉시 롤백 가능 | 인프라 비용 2배 |
| Canary | 일부 트래픽만 새 버전으로 | 위험 최소화 | 구현 복잡도 높음 |
| Recreate | 기존 전체 중단 후 새 버전 배포 | 단순함 | 다운타임 발생 |
선택 기준:
- 다운타임 허용 여부: 허용 불가 → Blue-Green 또는 Rolling
- 위험 허용도: 낮음 → Canary로 점진적 배포
- 인프라 비용: 제한적 → Rolling Update
- 롤백 속도: 즉시 필요 → Blue-Green
배포 전략은 별도 글에서 자세히 다룹니다. 여기서는 파이프라인의 Deploy 단계에서 "배포 전략을 선택해야 한다"는 점만 인지하면 됩니다.
11. 정리
- CI/CD 파이프라인은 Source → Build → Test → Deploy의 기본 구조를 가집니다. 조직의 요구사항에 따라 보안 스캔, 승인 게이트, 모니터링 단계가 추가됩니다.
- CI는 "코드 품질을 자동으로 검증"하고, CD는 "검증된 코드를 안전하게 배포"하는 역할입니다. 둘 다 있어야 완전한 자동화입니다.
- 도구 선택보다 "각 단계에서 무엇을 검증할 것인가"를 먼저 설계합니다. 도구는 요구사항에 맞춰 선택합니다.
- 파이프라인 보안은 Secret 관리, Action 버전 고정, 최소 권한 원칙이 핵심입니다.
- 빠른 피드백(CI 10분 이내)과 롤백 전략이 운영 안정성을 결정합니다.
참고 문서
'DevOps' 카테고리의 다른 글
| Blue-Green Deployment와 Rolling Update 차이: 배포 전략 선택 기준 (0) | 2026.06.07 |
|---|---|
| GitHub Actions로 Docker 이미지를 빌드하고 배포하기: CI/CD 파이프라인 실습 (0) | 2026.06.06 |
| GitHub Actions와 Jenkins 차이: CI/CD 도구 선택 기준 (0) | 2026.06.05 |
| Terraform S3 Backend와 State Lock 구성하기: 팀 협업을 위한 원격 상태 관리 (0) | 2026.05.31 |
| Terraform State란 무엇인가: 상태 관리의 개념과 실무 운영 전략 (0) | 2026.05.28 |



